


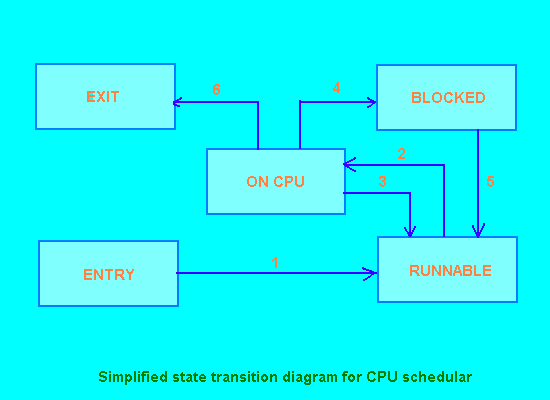
During its lifetime, a Linux process may be in one of several states, the main ones being:
Each process in Linux is represented internally by a struct task_struct, which contains the details of much of the environment in which the process executes. This structure is declared in the file:
/usr/src/linux/include/linux/sched.h
and the structure is dynamically allocated to the process in the do_fork() kernel function when the process is first created. The do_fork() function is contained in the file:
/usr/src/linux/kernel/fork.c
One of the members of the task_struct is called counter, and we shall see that it plays an important role in the scheduling of the process. The higher the value of counter in a TASK_RUNNING process, the more likely it is to be chosen to run the next time the scheduler is executed. Values of counter usually lie in the range 0 to 70, though in some circumstances, values outside this range are possible.
A process executing on the CPU will be required to give it up, so other processes may take a turn, in four main situations:
Conceptually, the Linux scheduler has remained virtually unchanged since its early days, though the 1.3 kernel versions have seen the code tidied up on several occasions, and have seen support added for multi-processor systems. For a single processor, the operation of the scheduler is quite straightforward, and we shall examine it in some detail.
The scheduling task itself is performed by a single function within the kernel called schedule(). This function is contained in the file:
/usr/src/linux/kernel/sched.c
The following pseudo code program details the steps taken by a single-processor version of the schedule() kernel function:
Execute any functions on the scheduler task queue FOR each process IF the process has a real time interval timer running IF the interval timer has expired Send a SIGALRM to the process Restart the interval timer if required END_IF END_IF IF the process state is TASK_INTERRUPTIBLE IF process has had a signal or has an expired timeout Set process state to TASK_RUNNING END_IF END_IF ENO_FOR FOR each process IF process state is TASK_RUNNING Remember the process with the highest counter value END_IF ENO_FOR IF all runnable processes have a counter value of zero FOR each process Recalculate process counter value from its priority END_FOR END_IF Switch context to the remembered highest counter process
As you can see, this is a very simple scheduling algorithm that depends largely on the counter value to determine how likely a process is to run and, when it does run, the size of its time slice.
In kernels which can support multiple processors there is a simple modification to the way in which the counter value is used to select the next process to run. Instead of just using the counter on its own, there are extra terms added to give some advantage to processes on the same processor and also to give a small advantage to the current process.
With these notes and a copy of your Linux kernel scheduler source code to hand, it should be fairly easy for you to run through the code and sort out how it works.