


In trying to perform its task, the scheduler has various objectives that it must try to achieve. And, as we shall see, several of these objectives will make demands on the scheduler that will pull in opposite directions. Among the more important objectives are:
An obvious way in which these objectives conflict is with regard to user requests. Here, it seems as though user requests should be favored in some way, though this obviously conflicts with the idea of giving all processes a fair share of the CPU.
One problem that the scheduler faces immediately is that, in general, very little is known about a process when it starts up. In particular, such things as how long the process will use the CPU on average before it has to stop to wait for some I/O to take place, and how long on average the process must wait for an I/O event to take place once it is requested, are unknown.
Another question is what to do with a process which uses a very large amount of CPU time before it does any I/O; can it be allowed just to go on hogging the processor? Well, obviously it can't, otherwise such a process could virtually stop all the other processes from making any progress.
This implies that there needs to be some mechanism for switching the CPU to another process when the current process has had long enough. But where is the decision to do this taken and how?
In general, there are two possibilities here, the first is to allow the processes themselves to release control of the CPU voluntarily when they have had a reasonable amount of time on the CPU, and the second is to find some mechanism to force a process to release its CPU control. The first of these is called non-preemptive scheduling and the second is called preemptive scheduling.
As we shall see when we look at threads, it is perfectly feasible to run a system of co-operating pieces of code that use non-preemptive scheduling to switch between them. However, for process scheduling in a multi-user environment, it is usually safer to assume that the processes may be, at best, unaware of each other's existence or, at worst, positively antagonistic towards each other in terms of their CPU use.
Consequently, in a multi-user environment, preemptive scheduling is used almost without exception and Linux is no exception.
The way that this is achieved is that each process is given a maximum length of time it will be allowed to have on the CPU without a break. In addition, the system will generate fairly rapid and periodic clock timer interrupts, which will be counted and used to determine when the process has had its allocated time slice.
When the time slice of the current process has elapsed, the scheduler will be forced to run to determine if there is another process ready to run and more eligible to run than the process whose time slice on the CPU has just expired. If there is, then it will be run in place of the current process. If there is not, then the current process can be allowed to continue.
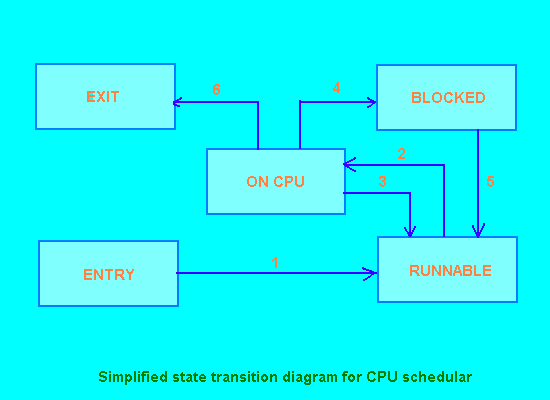
Obviously, from the previous discussion, there are several states in which a process may find itself, and several transitions between states that can occur in response to various events. Figure 1 shows a greatly simplified state transition diagram for processes under the control of the CPU scheduler and labels six transitions between the states which occur in the following circumstances:
Surprisingly perhaps, this state transition diagram is generally applicable regardless of the actual algorithm used by the CPU scheduler to determine which process should run next.
There are many possible algorithms which can be used for CPU scheduling, including lots of theory about which is best in various sets of circumstances. However, rather than engage in a general discussion of scheduling algorithms here, we shall just concentrate on the details of the actual Linux scheduling algorithm itself