


For the purposes of this discussion we will consider that a process consists of three separate parts, illustrated in Figure 1.
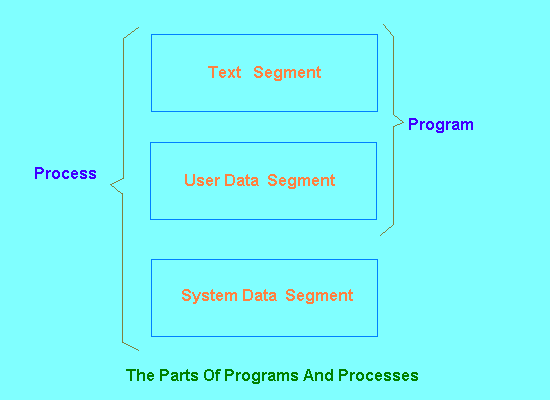
The text segment holds the machine code instructions that are to be executed. The segment is read-only (so you can't write self-modifying code here), which allows the possibility of sharing the segment between two or more process on the system that are running the same program. For instance, if several users are all running bash as their shell, there need only be one copy of the program instructions in memory, which they can all share.
The user data segment holds all the data upon which the process will operate directly as it executes, including all the variables that the process will use. Obviously, as the information contained here can be changed, each process needs its own private user data segment, even processes which are sharing a text segment.
The system data segment effectively holds the environment in which the program will run. Indeed, this is the distinction between programs and processes. A program is a static thing on disk consisting of a set of instructions and data which are used to initialize the text and user data segments of a process. The process is a dynamic thing, an execution environment requiring the interaction of the text, user data and system data segment information all running together.
Under Linux, there is only one way that an existing process can start up a new process for you and that is to use the fork() system call:
#inciude <unistd.h> pid_t fork(void);
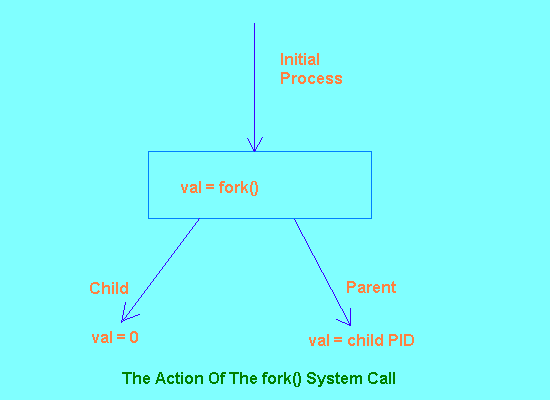
Conceptually, what happens with fork() is that the process which makes the fork() call becomes the parent of a new process which is created. The two processes are identical in terms of the contents of their text and user data segments, and almost identical in terms of their system data segments as well. The only difference between the processes is in a small number of attributes which have to be different (such as the PID, for instance, which has to be unique for each process). Once the child process has been created, then both the parent and child continue execution from inside the fork() call. This means that the next action for both processes is to return from fork() with its return value.
There doesn't seem much point in having two virtually identical processes running, unless there is some way to get them subsequently to perform different actions. This is made relatively simple by the fact that fork() returns a different value to the two processes. To the parent process it returns the PID of the newly created child, while to the child process it returns the value 0. As normal process IDs only start numbering from 1 with the init process, the fork() system call cannot return the value 0 to the parent as the PID of the new child. Therefore, if fork() does return a 0 then it must be to a new child process. If it returns a non-zero value then it must be the PID of a child process being returned to the parent (or -1 on error). This idea is illustrated in Figure 2.
The following code is a simple program to demonstrate the fork() call in action:
#include <sys/types.h>
#include <unistd.h>
main()
{
pid_t val;
printf("PID before fork(): %d\n", (int) getpid());
if (val = fork())
printf("Parent PID: %d\n", (int) getpid());
else
printf("Child PID: %d\n", (int) getpid());
}
When this program is run it should generate three lines of output. The first will display the PID of the process before the fork() call is executed, and the other two lines of output will be generated by the parent and child processes after the fork(), giving the PID of each process. A typical output from the program could be:
$ forktest PID before fork(): 490 Parent PID: 490 Child PID: 491
After the execution of a fork() call most of the attributes of the parent process are available unchanged in the child. The main unchanged attributes are:
In addition to this, all of the file descriptors which are associated with open file descriptions in the parent process will be duplicated in the child. This means that the child's file descriptors and the parent's file descriptors will both point to the same open file descriptions, as shown in Figure 3.

This is a very important concept, as we shall see later, because it allows a process to open files in advance, knowing that they will be pre-opened and immediately available to its child processes after a fork() call.