


Starting a mew thread just means creating a struct context for the thread and allocating a block of memory for its stack. These data structures can then be initialized and added to the scheduling loop to get the opportunity to run. It all sounds straightforward when you say it fast but in fact it is a little bit tricky and requires some attention to detail. The tricky bit is initializing the thread's stack, as several values need to be hand crafted into the empty stack before it can be used:
new_thread(int (*start_addr) (void), int stack_size)
{
struct context *ptr;
int esp;
/* 1 */
if (!(ptr = (struct context *)malloc(sizeof(struct context))))
return 0;
/* 2 */
if (!(ptr->stack = (char *)malloc(stack_size)))
return 0;
/* 3 */
eap = (int) (ptr->stack+(stack_size-4));
*(int *)esp = (int)exit_thread;
*(int *)(esp-4) = (int)start_addr;
*(int *)(esp-8) = esp-4;
ptr->ebp = esp-8;
/* 4 */
if (thread_count++)
{
/* 5 */
ptr->next = current->next;
ptr->prev = current;
current->next->prev = ptr;
current->next = ptr;
}
else
{
/* 6 */
current = ptr->next = ptr->prev = ptr;
switch_context(&main_thread, current);
}
return 1;
}
The new_thread() function takes two parameters, the first is the address of the function where execution of this thread will begin and the second is the size of the memory block (in bytes) to allocate for stack space to the new thread. The numbered comments in the code are as follows:
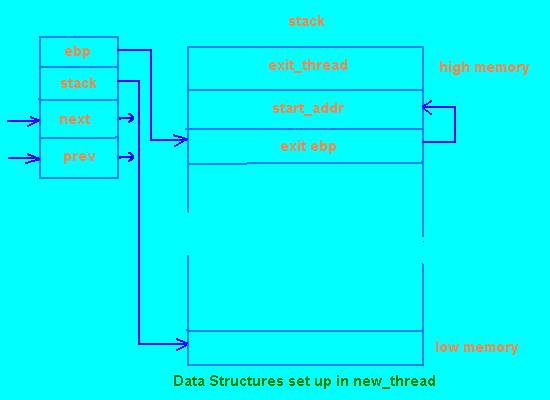
Figure 1 shows that the ebp element of the struct context associated with the new thread is set to point into the thread's stack. When a context switch is made to the new thread, this value is loaded into the CPU ebp register. The return from the switch_context() function then causes the stack pointer to point to the same stack location. Performing a stack pop into ebp loads this register appropriately and also makes the stack pointer point to the thread start function. Finally, performing a return from subroutine will pop the start address into the program counter, thus performing a jump to the beginning of the thread start function.
An extra twist is required when a thread's start function terminates in order to remove the thread from the scheduling loop and free its malloc()ed memory back to the system. These actions are performed by the exit_thread() function. So that you don't need to remember to call this function at the end of each thread's start function, a jump to the function is automatically crafted into the thread's stack. This means that the function is automatically executed when the thread's start function terminates, using a similar trick to the one which executed the start function in the first place.
The code for the exit_thread() function appears as follows:
static exit_thread(void)
{
struct context dump, *ptr;
/* 1 */
if (--thread_count)
{
/* 2 */
ptr = current;
current->prev->next = current->next;
current->next->prev = current->prev;
current = current->next;
free (ptr->stack);
free (ptr);
switch_context(&dump, current);
}
else
{
/* 3 */
free(current->stack);
free(current);
switch_context (&dunp, &main_thread);
}
}
The exit_thread() function terminates the thread pointed to by current. The fact that the exit_thread() function is declared to be static prevents it from being called from outside the library. The numbered comments are: